Windows10でドメインから抜ける方法について
今回は、Windows10でドメインから抜ける方法について紹介します。
Windows10でドメインを抜けてワークグループに参加するとドメインのアカウントは利用できなくなります。
その為、ローカルPCに管理者権限のアカウントを準備しておく必要があり、ワークグループに参加する際に準備した管理者アカウントで再ログインする必要があります。
また、ワークグループのアカウントに切り替えると今まで利用していたアプリに付随するデータ等がほぼ参照できなくなる為、ドメインから抜ける前に事前移行をしておく必要があります。
改めて、ドメインから抜ける際の手順を以下に記載します
1) ローカルPCに管理者権限を持つアカウントを作成する
2)作成したアカウントに対して、事前にアプリケーションのデータ移行を行う
3)ドメインから抜けてワークグループに参加する
次に、上記手順を実施する際のTipsを紹介します。
ローカルPCに管理者権限を持つアカウントを作成する
ローカルPCに管理者権限のアカウントを追加する場合、Microsoftは「スタート」「設定」「アカウント」からの設定を推奨していますが、「コンピュータの管理」「ローカルユーザーとグループ」「ユーザー」からの方が簡単に作成できます。
 ただし「コンピュータの管理」自体も管理者権限が必要な為、管理者権限のないアカウントをご利用中の場合は、アカウント管理部門(情シス等)に確認が必要です。
ただし「コンピュータの管理」自体も管理者権限が必要な為、管理者権限のないアカウントをご利用中の場合は、アカウント管理部門(情シス等)に確認が必要です。
作成したアカウントに対して、事前にアプリケーションのデータ移行を行う
最初に記載した通り、ワークグループのアカウントに切り替えると今までドメインアカウント側で利用していたアプリに付随するデータ等がほぼ参照できなくなる為、ドメインアカウントとワークグループアカウントの両方をログイン出来る状態にしておくと、データ移行をスムーズに行えます。
(ドメインアカウント側でアプリのデータエクスポートを行って、ワークグループアカウント側でインポートを行う等)
また、データ移行を行う場合、アプリによっては移行元(ドメインアカウント)のフォルダーを直接参照する必要があるので、以下に参照方法を記載します。
Windowsの場合、C:\Users配下にアカウント単位のフォルダーが作成されます。
例) C:\Users\user1(ドメインユーザー) C:\Users\user2(ワークグループユーザー)
次に、各アプリのデータは、アカウント配下のAppData\Localフォルダーに格納されることが多いので、その配下に作成されたアプリ毎のフォルダーから移行を行います。
(アプリによってはデータをレジストリに格納することもあるので、その辺りはアプリの仕様を確認してみてください)
例) C:\Users\user1\AppData\Local(ドメインユーザーのアプリデータ格納場所) C:\Users\user2\AppData\Local(ワークグループユーザーのアプリデータ格納場所)
最後に、上記AppDataフォルダーですが、デフォルトは隠しファイルになっているので、エクスプローラーの「表示」メニューにて隠しファイルを表示する様に設定変更が必要です。

ドメインから抜けてワークグループに参加する
ドメインから抜けてワークグループに参加する方法は以下のサイトを参考にして下さい。
一度ドメインアカウントから抜けると(ドメインの管理部門に対応してもらわない限り)再ログインできなくなりますので、抜ける前に必ずデータ移行を行っておく必要があります。
rcloneによるファイルアーカイブ
以前、以下の記事
で、Googleドライブをストレージとして使うためにgoogle-drive-ocamlfuseやrcloneを試したのですが、最終的にrcloneを使うことにしたので、セットアップについて記事にしたいと思います。
インストールについては、以下のページに書いてある通りのコマンドでできました。
$ sudo -v ; curl https://rclone.org/install.sh | sudo bash
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 4669 100 4669 0 0 3767 0 0:00:01 0:00:01 --:--:-- 3768
Archive: rclone-current-linux-amd64.zip
creating: rclone-v1.60.1-linux-amd64/
inflating: rclone-v1.60.1-linux-amd64/git-log.txt
inflating: rclone-v1.60.1-linux-amd64/README.txt
Updating index cache for path `/usr/local/man/man1'. Wait...done.
Checking for stray cats under /usr/local/man...
Checking for stray cats under /var/cache/man/oldlocal...
1 man subdirectory contained newer manual pages.
1 manual page was added.
0 stray cats were added.
0 old database entries were purged.
rclone v1.60.1 has successfully installed.
Now run "rclone config" for setup. Check https://rclone.org/docs/ for more details.
そして、設定をします。
$ rclone config Current remotes: Name Type ==== ==== e) Edit existing remote n) New remote d) Delete remote r) Rename remote c) Copy remote s) Set configuration password q) Quit config e/n/d/r/c/s/q> n Enter name for new remote. name> google-drive_backup Option Storage. Type of storage to configure. Choose a number from below, or type in your own value. 1 / 1Fichier \ (fichier) 2 / Akamai NetStorage \ (netstorage) ・ ・ ・ 18 / Google Drive \ (drive) ・ ・ ・ Storage> 18 Option client_id. Google Application Client Id Setting your own is recommended. See https://rclone.org/drive/#making-your-own-client-id for how to create your own. If you leave this blank, it will use an internal key which is low performance. Enter a value. Press Enter to leave empty.
ここでGoogleドライブのクライアントID(とOAuthのsecret)を作ります。 以下のページ
に作り方が載っていますが、以下の方が参考になりました。
GoogleCloudConsoleで作ったIDとsecretを入力します。
client_id> XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Option client_secret.
OAuth Client Secret.
Leave blank normally.
Enter a value. Press Enter to leave empty.
client_secret> XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Option scope.
Scope that rclone should use when requesting access from drive.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / Full access all files, excluding Application Data Folder.
\ (drive)
2 / Read-only access to file metadata and file contents.
\ (drive.readonly)
/ Access to files created by rclone only.
3 | These are visible in the drive website.
| File authorization is revoked when the user deauthorizes the app.
\ (drive.file)
/ Allows read and write access to the Application Data folder.
4 | This is not visible in the drive website.
\ (drive.appfolder)
/ Allows read-only access to file metadata but
5 | does not allow any access to read or download file content.
\ (drive.metadata.readonly)
scope> 1
Option service_account_file.
Service Account Credentials JSON file path.
Leave blank normally.
Needed only if you want use SA instead of interactive login.
Leading `~` will be expanded in the file name as will environment variables such as `${RCLONE_CONFIG_DIR}`.
Enter a value. Press Enter to leave empty.
service_account_file>
Edit advanced config?
y) Yes
n) No (default)
y/n> n
Use auto config?
* Say Y if not sure
* Say N if you are working on a remote or headless machine
y) Yes (default)
n) No
y/n> n
Option config_token.
For this to work, you will need rclone available on a machine that has
a web browser available.
For more help and alternate methods see: https://rclone.org/remote_setup/
Execute the following on the machine with the web browser (same rclone
version recommended):
rclone authorize "drive" "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
Then paste the result.
Enter a value.
ここで、Googleドライブへのアクセスを認証するtokenを入力します。 OAuth認証が必要なため、上に表示されているrclone authorizeコマンドをサーバーではなくブラウザが使える環境(手元のPCにrcloneを入れるなど)で実行します。
途中でブラウザでのOAuth認証が実行され、以下のようになります。
mypc$ rclone authorize "drive" "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" 2022/12/16 17:41:12 NOTICE: Config file "/xxx/xxxx/xxx/rclone.conf" not found - using defaults 2022/12/16 17:41:12 NOTICE: Make sure your Redirect URL is set to "http://127.0.0.1:53682/" in your custom config. 2022/12/16 17:41:12 NOTICE: If your browser doesn't open automatically go to the following link: http://127.0.0.1:53682/auth?state=XXXXXXXXX 2022/12/16 17:41:12 NOTICE: Log in and authorize rclone for access 2022/12/16 17:41:12 NOTICE: Waiting for code... 2022/12/16 17:41:23 NOTICE: Got code Paste the following into your remote machine ---> [TOKEN] <---End paste
上記tokenをサーバーに貼り付けます。
config_token> [TOKEN]
Configure this as a Shared Drive (Team Drive)?
y) Yes
n) No (default)
y/n> n
Configuration complete.
Options:
- type: drive
- client_id: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
- client_secret: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
- scope: drive
- token: {XXXXXXXXXXXXXXXXXXXXXXXXXXXX}
- team_drive:
Keep this "google-drive_backup" remote?
y) Yes this is OK (default)
e) Edit this remote
d) Delete this remote
y/e/d> y
Current remotes:
Name Type
==== ====
google-drive_backup drive
e) Edit existing remote
n) New remote
d) Delete remote
r) Rename remote
c) Copy remote
s) Set configuration password
q) Quit config
e/n/d/r/c/s/q> q
これでrcloneコマンドでGoogleドライブに接続ができます。
さらに、共有ドライブに接続するために、設定ファイル~/.config/rclone/rclone.confの該当項目にドライブID(team_drive)を設定します。
ドライブIDはドライブURLのhttps://drive.google.com/drive/folders/以下の部分です。
$ vi .config/rclone/rclone.conf
[google-drive_backup]
type = drive
client_id = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
client_secret = XXXXXXXXXXXXXXXXXXXXXXX
scope = drive
token = {XXXXXXXXXXXXXXXXXXXXXXXXXXXX}
team_drive = [ドライブID]
以上で、rcloneのコマンドが使えるようになります。
$ rclone lsd google-drive_backup:
-1 2022-12-16 00:00:00 -1 backup
これで、rclone copyなどでファイルを移してアーカイブできます。
Shadow DOMのclickイベントを取得する
Shadow DOMの要素がクリックされたことを記録することになり、試行錯誤した記録です。
記録する対象はrss-listという名前のコンポーネントです。 イベントを記録するrecoreEvent関数へevent変数を渡していますが、event変数の中身がShadow DOMとなっておりクリックされた要素を取得することができません。
const onClick = (event) => { recordEvent(event); // #shadow-root }; document.querySelector('rss-list').addEventListener('click', onClick);
そこで、以下を参照に実装を行いました。 composedPath()でイベントが通過したパスを取得し、クリックされた要素がShadow DOM内にあるかチェックを行うに変更しました。
const onClick = (event) => { if ('composed' in event && typeof event.composedPath === 'function') { const path = event.composedPath(); const targetElement = path[0]; const shadowFound = path.length ? path.filter((i) => !targetElement.shadowRoot && !!i.shadowRoot).length > 0 : false; if (!targetElement || !targetElement.tagName) { return; } if (!shadowFound) { return; } recordEvent(targetElement); // <a /> } }; document.querySelector('rss-list').addEventListener('click', onClick);
これで、Shadow DOMのclickイベントを取得することが出来るようになりました。
PostgreSQLのバックアップ処理で使用するディスク容量を減らす工夫
イートスマートが提供するサービスでは、データベースにPostgreSQLを利用しています。 レプリケーションを行うことで冗長性を確保することに加え、毎日バックアップを作成しています。 このバックアップを作成する処理が使用するディスク容量が増えてきたので、減らす工夫を行ってみました。
以前のバックアップ処理
以下の流れでバックアップを行っていました。 バックアップの対象はすべてのテーブルではありません。
1.psqlコマンドで、COPYで指定したテーブルをTOで指定したファイルへ出力 2. gzipコマンドで、1で出力したファイルを圧縮 3. tarコマンドで、2で圧縮したファイルをアーカイブにする 4. 2で圧縮したファイルを削除する
バックアップの対象は数十のテーブルです。 これらのテーブルに対して1と2の処理を実行すると、圧縮されたファイルが大量に作成されます。 3でtarにアーカイブするタイミングで、2の圧縮ファイルと合わせて大量のディスク容量が消費されてしまいます。
新たなバックアップの処理
改善を試みたのは以下の2つです。
- 大量のディスク容量が消費される
- バックアップから完全なリストアができない
1に関しては、テーブルの内容を都度tarへアーカイブすることで解消を行いました。 psql/COPYの後にgzipで圧縮していたものを、pg_dumpとgzipを組み合わせています。
- psql -d <データベース名> -c "COPY <テーブル名> TO '<バックアップファイル>'" > /dev/null - gzip <バックアップファイル> + pg_dump --data-only --table=<テーブル名> <データベース名> | gzip > <バックアップファイル>.gz
アーカイブを作成する処理を、すべてのテーブルのバックアップを作成してからまとめて行うのではなく、バックアップファイルを都度行うようにしています。
- tar cfP <アーカイブファイル> *.gz + tar rfP <バックアップファイル> <バックアップファイル>.gz
2に関しては、データのバックアップはあるものの、スキーマやシーケンスのバックアップが無いため、完全なリストアができない状態でした。 このため、まずスキーマをバックアップする処理を追加しました。
+ pg_dump -h 127.0.0.1 -U postgres --schema-only <データベース名> > <スキーマのバックアップファイル>.sql
シーケンスはpg_classから取得して、テーブルと同様にバックアップの対象に追加しました。
SELECT c.relname FROM pg_class c LEFT join pg_user u ON c.relowner = u.usesysid WHERE c.relkind = 'S';
リストアは、アーカイブファイルを展開したものをpsqlコマンドで実行することで行うことができます。
+ psql -d <データベース名> -f "<スキーマのバックアップファイル>.sql" + zcat "<バックアップファイル>.gz" | psql -U postgres -d <データベース名>
まとめ
以上の工夫で、バックアップ処理で使用するディスクを最大2割程度減らすことができました。
Reactでのページ離脱時のメッセージ表示について
現在Reactで管理画面系のフォームを作っているのですが、少しややこしい画面構成 + 使う人のリテラシーが高くない、という状態なので、フォームをsubmitせずにページ離脱しようとした場合、確認メッセージを表示しようということになりました。
画面遷移時の確認メッセージ表示は、beforeunloadイベントを使えば実現できそうです。
上記ページに従うと、Reactで使うためにはuseEffectを使って、クラスで言うcomponentDidMountのタイミングでaddEventListener、componentWillUnmountのタイミングでremoveEventListenerを実行すると良さそうです。 add時とremove時に同じ関数の実体を渡す必要があるので、
const handleBeforeUnloadEvent = (event) => {
event.preventDefault();
event.returnValue = "";
};
useEffect(() => {
window.addEventListener("beforeunload", handleBeforeUnloadEvent, true);
return () => window.removeEventListener("beforeunload", handleBeforeUnloadEvent, true);
}, []);
でできそうです。
さらに、フォームのsubmit時は画面遷移の確認メッセージは出したくないので、onSubmitの最後に
const handleSubmit = (e) => {
// validate + confirm処理
…
window.removeEventListener("beforeunload", handleBeforeUnloadEvent, true);
}
としてみたのですが、submitすると確認メッセージが表示されてしまいます。
上で書いたように、add時とremove時は同じ関数の実体を渡す必要があると理解しているので、実体が違うのかな?でもどうすれば同じものを渡せるのかな?と試行錯誤していたのですが、以下の記事でuseCallbackフックというのを見つけました。
で、これを使ってはじめの関数定義を
const handleBeforeUnloadEvent = useCallback((event: BeforeUnloadEvent): void => {
event.returnValue = "";
},[]);
としてみたところ、無事submit時はメッセージが表示されなくなりました!
いやあ、Reactって奥が深いというか知らないことが多いというか仕様がややこしいというか…。でも動くとうれしいですね!
Googleフォームの回答を複数ユーザーへメール通知する方法について
通常、Googleフォームに回答があった場合に作成したオーナーにのみメール通知を設定することが可能です。
また、複数のユーザーで通知を受け取る場合、GASの設定を行えば可能ですが、若干コーディングが必要な為、それ以外の方法がないか調べたとろこスプレッドシート経由で受信することが可能なのでその方法を紹介します。
Googleフォームとスプレッドシートを連携させる
1) フォーム上部の「回答」をクリックする
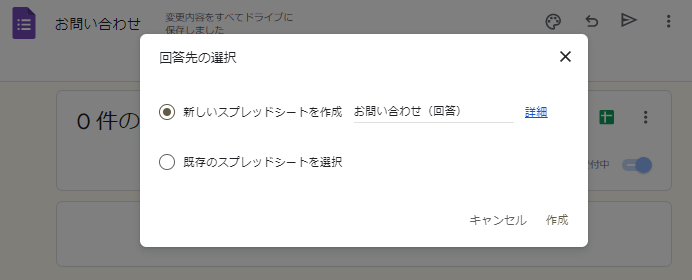
2) スプレッドシートのアイコンをクリックする

3)「新しいスプレッドシートを作成」を選択し、スプレッドシートを作成する
スプレッドシートの通知ルールを設定する
1)メニューバーの「ツール」から、「通知設定」-「通知の編集」を選択する

2)「ユーザーがフォームを送信したとき」と「その都度」を選択し、「保存」する

3)通知ルールの設定を「完了」する

複数のユーザーで通知を受け取る場合ですが、上記スプレッドシートを共有して「スプレッドシートの通知ルールを設定」を通知を受信したいユーザー毎に設定することで可能となります。
また、Googleフォーム上で回答を確認した場合は回答日時が分かりませんが、スプレッドシートと連携しておくと一覧上にタイムスタンプ(回答日時)が表示されるので更に分かりやすくなります。
ubuntu serverからSAKURAのVPCルーターへのL2TP/IPsec接続
現在、訳あってオフィスにあるノートPCにubuntu serverをインストールし、SAKURAのVPCルーターへL2TP/IPsec接続の設定をしています。
CUI環境でややこしい設定できるのか?と心配していたのですが、下記の記事に書いてある通りNetworkManager-L2TPとnmcliを使って問題なく接続できたので、紹介します。
Ubuntu Server 18.04 (CUI環境)でも簡単に L2TP over IPsec がしたい - Qiita
やり方
ほぼこの記事に書いてある通りの操作なのですが、まずNetworkManagerをインストールします。
apt install network-manager network-manager-l2tp
ネットワークをNetworkManagerで管理するために、以下のように設定を行います。
# cat /etc/netplan/50-cloud-init.yaml
network:
version: 2
renderer: NetworkManager
なお、インストール時に生成された設定ファイルはファイル名を変更して無効にしました。
# ls 00-installer-config-wifi.yaml.bk 00-installer-config.yaml.bk 50-cloud-init.yaml
この後、rebootしたり、nmtuiを使ってサーバーのネットワークの設定を行いました。(nmtuiって便利ですね!)
その後、nmcliコマンドでVPN接続を作成します。
# nmcli connection add \ connection.id vpn-sakura(idは適切なものでOK) \ con-name vpn-sakura(nameは適切なものでOK) \ type VPN vpn-type l2tp ifname -- connection.autoconnect no ipv4.method auto \ vpn.data "gateway = VPCルーターの対向IP, ipsec-enabled = yes, ipsec-psk = SAKURAの管理画面で設定するsecret, ipsec-ike=aes256-sha1-modp1024, ipsec-esp=aes256-sha1-modp1024, mru = 1400, mtu = 1400, password-flags = 0, refuse-chap = yes, refuse-mschap = yes, refuse-pap = yes, require-mppe = yes, user = VPNユーザー名" \ vpn.secrets password=VPNユーザーのパスワード
※ 諸元は リモートアクセス(VPN)設定 | さくらのクラウド ドキュメント を参考にしました
※※ ipsec-ikeとipsec-espの値は、上記諸元と GitHub - nm-l2tp/NetworkManager-l2tp: L2TP and L2TP/IPsec support for NetworkManager を参考にしました
あとは、nmcli conn コマンドでネットワークを有効にすればつながります(ハズ)。
nmcli conn up vpn-sakura
起動後に/var/log/syslogなどで、無事接続ができたかを確認してみて下さい!